6 minutes
Qmq_delay
背景
最近在调研延迟消息的设计和研发, 其中, 目前开源并在线上大规模使用的主要是 去哪儿的qmq, 本文主要针对 qmq 中的延迟消息实现进行分析
问题
作为一款延迟消息服务, 需要解决一下问题:
- 延迟消息的底层存储
- 延迟消息的投递方式
- 延迟消息怎么保证稳定的到期
- 延迟消息到期怎么投递
- 延迟消息是否可以取消
- 主从同步
设计
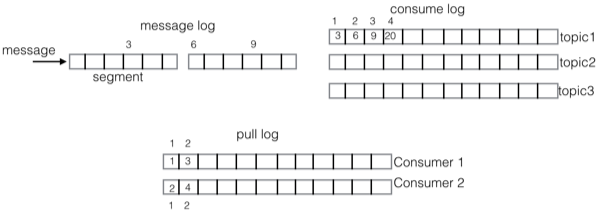
qmq 的延迟设计中, 所有的消息投递到 message log, message log 相当于 wal, 会有一个IterateOffsetManager 异步读取 message log 构建 schedule log 和 hash wheel, schedule log 是每个目标到期时间的文件, 默认每分钟一个文件, 时间间隔可以定制. hash wheel 是内存的多层时间轮, 所有后续的延迟消息 以及 到期的schedule log文件的消息 都会加载到内存中. 消息到期后, 会投递给 正常的消息服务的broker (投递会目标subject)
底层存储
qmq 本身设计了一套文件存储形式, 延迟功能基于这套存储进行了封装和实现, 除此之外, 延迟功能在内存中也维护了一份 时间轮的消息索引, 这里主要分析文件侧实现. 在延迟消息存储的设计中, 主要是以下模块:
-
LogSegment&LogManager: qmq底层文件存储 和 文件目录管理(以及recover) 的实现, 延迟消息和普通消息基于这个做定制化. 仅负责写入和读取的行为及结果, 不管理内容格式
-
MessageLog&MessageSegmentContainer: 基于上面的log机制 实现了 延迟消息的存储, 主要是 存储内容的定义, MessageLog 对外暴露写入接口. 相当于WAL
-
LogIterateService: 读取messagelog的消息分发给订阅者
-
ScheduleLog & ScheduleSet & ScheduleSetSegmentContainer: 定时任务的存储. 通过订阅 LogIterateService 将messageLog的消息添加到 schedule log.
-
DispatchLog & DispatchLogSegment & DispatchLogSegmentContainer: dispatch日志的存储, 用来确定在重启后, 当前刻度内哪些消息已经投递, 避免重复投递
-
DefaultDelayLogFacade: 文件对外交互的接口, 所有文件相关的操作: messageLog、scheduleLog、dispatchLog 都是从这里进入的.
在qmq的设计中, 单个文件和文件的管理分成了两个抽象, XXXXSegment 和 XXXSegmentContainer, XXXXSegment 实现写入和加载文件内容, XXXSegmentContainer 负责对多个文件管理, 读写最新文件和遍历所有文件.
MessageLog
存储
MessageLog 是 延迟消息的WAL, 并且充当了 削谷填峰 的角色, MessageLog 里面存储的是完整的消息, 格式如下:
4 // magic code (消息版本)
+ 1 // attributes (ATTR_MESSAGE_RECORD=0, 表示正常记录, 写入消息的时候, 会检查 剩余空间大小, 比如不足以写入消息, 就会写入一个 ATTR_EMPTY_RECORD=1. 还定义了一个ATTR_SKIP_RECORD, 已经废弃)
+ 8 // timestamp (当前时间戳)
+ 8 // message logical offset (sequence, 递增计数)
+ 2 // subject size
+ subject
+ 8 // payload crc32
+ 4 // payload size
+ payload
因为所有的延迟消息最终存储在 scheduleLog(分析如下) 上, 因此 messagelog 的历史消息可以删除, 按照qmq的设计, 延迟消息使用低容量高性能的ssd盘来提高吞吐量, 那么message log什么时候进行删除呢?
删除
DefaultStorage在#start的时候, 会启动定时任务 logCleanerExecutor 执行删除, 删除间隔配置: config.getLogRetentionCheckIntervalSeconds(), 单位是秒. 定时任务 logCleanerExecutor 会启动多种删除任务, 其中就包括 messageLog#clean, 核心代码如下:
public void deleteExpiredSegments(final long retentionMs, DeleteHook afterDeleted) {
final long deleteUntil = System.currentTimeMillis() - retentionMs;
Preconditions.checkState(deleteUntil > 0, "retentionMs不应该超过当前时间");
Predicate<LogSegment> predicate = segment -> segment.getLastModifiedTime() < deleteUntil;
deleteSegments(predicate, afterDeleted);
}
通过入参可以知道, 文件的删除是按照 retentionMs(保留时间) 的维度进行删除的, 那么, 这就需要保证 retentionMs 之前的消息被同步到scheduleLog. 因此建议 retentionMs 不建议设置的太小.
补充: 在每个消息的开头, 都会有如下头部信息: (运行测试下)
4 // magic code (版本标志, 目前版本3)
+ 1 // 固定标志2
+ 8 // 当前时间戳
+ 4 // untilWhere, 绝对偏移量. 通过取余 `PER_SEGMENT_FILE_SIZE` 节省存储量
问题 这里的message log是按照时间删除的, 所以需要尽量保证 messagelog 的消息及时构建到 schedule log.
ScheduleLog
存储 scheduleLog 异步从 messageLog 读取消息构建, 按照投递时间组织, 每个小时一个文件, scheduleLog 内的消息是完整的消息内容, 格式如下:
4 // magic code
+ 1 // attributes (ATTR_MESSAGE_RECORD=0, 表示正常记录, 写入消息的时候, 会检查 剩余空间大小, 比如不足以写入消息, 就会写入一个 ATTR_EMPTY_RECORD=1. 还定义了一个ATTR_SKIP_RECORD, 已经废弃)
+ 8 // timestamp (当前时间)
+ 8 // scheduleTime (消息的到期时间)
+ 8 // sequence (递增计数)
+ 4 // messageIdBytes len
+ messageIdBytes
+ 4 // subject len
+ subject
+ 8 // payload crc32
+ 4 // payload size
+ payload
除了本地文件存储, 还会构建一个 ScheduleIndex 对象, 用来构建 timewheel. 那么, scheduleLog 是怎么从messageLog构建的呢? 在 DefaultDelayLogFacade 的实现中, 通过 FixedExecOrderEventBus 将 LogIterateService 读取的消息 分派给 注册的订阅者, 其中就包括 scheduleLog, 可以参照:
bus.subscribe(MessageLogRecord.class, e -> {
AppendLogResult<ScheduleIndex> result = appendScheduleLog(e);
int code = result.getCode();
if (MessageProducerCode.SUCCESS != code) {
LOGGER.error("appendMessageLog schedule log error,log:{} {},code:{}", e.getSubject(), e.getMessageId(), code);
throw new AppendException("appendScheduleLogError");
}
func.apply(result.getAdditional());
});
bus.subscribe(MessageLogRecord.class, e -> {
long checkpoint = e.getStartWroteOffset() + e.getRecordSize();
updateIterateOffset(checkpoint);
});
bus的订阅者除了将消息写入到 scheduleLog, 还会更新 已经读取的 messageLog 的物理位置: iterateOffset, 这个会定时保存到checkpoint, 用于重启时候的恢复.
删除
和 messageLog 的删除调度在一个线程中, 因此也是定时调度的. 但是相比于 messageLog retentionMs 删除机制的不同, scheduleLog 的删除time计算比较复杂, 如下:
public void clean() {
long checkTime = resolveSegment(System.currentTimeMillis() - config.getDispatchLogKeepTime() - config.getCheckCleanTimeBeforeDispatch(), segmentScale);
for (DelaySegment<ScheduleSetSequence> segment : segments.values()) {
if (segment.getSegmentBaseOffset() < checkTime) {
clean(segment.getSegmentBaseOffset());
}
}
}
public boolean clean(Long key) {
if (segments.isEmpty()) return false;
if (segments.lastKey() < key) return false;
DelaySegment segment = segments.remove(key);
if (null == segment) {
LOGGER.error("clean delay segment log failed,segment:{}", logDir, key);
return false;
}
if (!segment.destroy()) {
LOGGER.warn("remove delay segment failed.segment:{}", segment);
return false;
}
LOGGER.info("remove delay segment success.segment:{}", segment);
return true;
}
其中, config.getDispatchLogKeepTime() 是 dispatch文件保存的小时数, config.getCheckCleanTimeBeforeDispatch() 是schdule在dispatchlog 删除前的时候. 使用两个配置参数, 虽然增加了用户的设置复杂度, 但是避免了用户的错误配置.
但是很明显, 这里schedulelog 的删除并没有 依赖 dispatchlog 的检查, 可能延迟消息还没有投递给下游, schedulelog 就要被删除. 因此建议两个时间设置的大些.
这点和 messagelog的clean删除类似, 也是基于保留时间的删除机制, 只是这个保留时间考虑了 dispatch log 的保留时间.
问题:
很显然, 这里也是无脑的删除. 而且值得注意的是, 这里的设计相当于 如果因为宕机导致历史消息保存了很久, 会消息丢失 (因为schedulelog没有了), 不过只要宕机时间不超过 删除的时间点, 问题不大.
宕机恢复 统一写
dispatch log
主流程逻辑
dispatch log 用来记录成功发送的消息的sequence, 文件存储单元也很简单, 如下:
8 // sequence
dispatch log 只有在 到期消息成功投递给下游后, 或者 slave 同步master dispatch log 的时候才会写入. 那么写入dispatch log 怎么使用呢?
dispatch log 只有在 server 重启的时候使用, 用来判断 schedule log 中的消息是否已经发送过, 如果已经发送过, 就不在发送, 如果没有发送, 就实例化一个 一个 timeout 任务给 WheelLoadCursor 调度. 为了加快判断, 这里使用了 LongHashSet, LongHashSet 本质上实现了 Long 的hashset, 使用 开址法 解决冲突.
调用下游失败, 这么么办? 目前是无限重试
删除逻辑
删除逻辑也是按照保存时间进行删除, 如下:
public void clean(LogCleaner.CleanHook hook) {
long deleteUntil = resolveSegment(System.currentTimeMillis() - config.getDispatchLogKeepTime(), segmentScale);
for (DelaySegment<Boolean> segment : segments.values()) {
if (segment.getSegmentBaseOffset() < deleteUntil) {
doClean(segment, hook);
}
}
}
需要注意的是, 和之前的删除逻辑不同的是, 这里的删除 添加了一个 hook 回调, 用来删除 schedulelog 的segment.
关于存储时间
因为qmq的延迟文件默认是1分钟一个, 那么, 一天就是 24 * 60 = 1440, 60天就是 1440 * 60 = 86400 < 9w文件, 默认程序的文件句柄限制是 1024, 可以通过 ulimit -n 查看, 需要手动修改配置, 需要以下两步:
- 修改
/etc/security/limits.conf, 如下
speng soft nofile 10240
speng hard nofile 10240
- 修改
/etc/pam.d/login,
session required /lib/security/pam_limits.so
另外也可以通过 cat /proc/sys/fs/file-max 命令查看 系统的文件数量限制. 需要注意的是, Linux 内核 2.6.25 以前,在内核里面宏定义是1024 * 1024,最大只能是100w(1048576),所以不要设置更大的值,如果Linux内核大于 2.6.25 则可以设置更大值.
在qmq的设计中, 最大支持两年, 大概就是 1036800 ~ 100w 个文件.
定时刷新
qmq 定时刷新的逻辑是统一触发的, 统一管理在 LogFlusher 中, 通过 抽象 FlushProvider 解耦了各log的flush实现逻辑(message log、 dispatch log、IterateOffsetManager), 每种log 都是一个单线程定时调度. 不同 FlushProvider 的实现中, 文件的flush实现基本一致, 唯一的差异是 flushOffset 需要存储. 需要注意的是, log flush 并没有 schedule log的实现, 因为 schedule log 是通过 IterateOffsetManager 异步从 message log 异步构建的, IterateOffsetManager#flush 第一步就会调用 scheduleLog#flush 实现.
message log、dispatch log 的flush间隔是: 500ms, IterateOffsetManager 的 flush 间隔是: 10 * 1000 ms. message log 和 dispatch log 仅仅是 调用 fileChannel#force, IterateOffsetManager#flush 的实现比较特殊, 在flush实现中, 会提前调用 schedulelog#flush, 还会存储 iterateOffsetManager 的 iterateOffset (CheckpointStore#saveCheckpoint), 作为checkpoint.
ScheduleLog在进程关闭的时候, 也会存储 各个时间点文件的offset的checkpoint.
这里的checkpoint实现中, 只有 iterateOffsetManager 有checkpoint, messageLog 和 dispatch log 并没有, 那么 messageLog 和 dispatch log 的recover 会花费很长时间, 参考 recovry.
定时删除
qmq的文件删除也是统一定时触发的, LogCleaner 会相继调用 messageLog、scheduleLog、dispatchLog 的clean方法
除了定时删除, dispatch log 的删除会回调触发 schedule log 的删除, dispatch log 删除的话, 就意味着对应的 schedule log 都已经没有意义了.
统一recovery
文件的recovery的巧妙在于 validator的抽象, 解耦了验证和文件处理.
messageLog
主要实现在 LogManager 的实例化中, 会先将每个文件映射到 java 的文件对象中, 然后尝试从倒数第二个文件开始恢复, 文件/segment 的内容验证 是通过 MessageLogSegmentValidator 实现, validator 有几种情况需要考虑:
- 文件全是合法消息
- 文件只有部分合法消息
- 文件因为无法填充消息, 预留了
ATTR_EMPTY_RECORD的空白 - 文件损坏
1、4都是不断读取消息解码就可以了. 2、3 需要根据解码失败的反馈得到, 比如 magic code、attribute code.
IterateOffsetManager
比较特殊, 因为本身只是个异步构建服务, 因此只需要存储已经读取的messagelog的位置, 在 实例化的时候完成.
schedule log
这个实现比较特殊, 在实例化 ScheduleSetSegmentContainer 的时候调用的 validator 是不起作用的, 只有在 ScheduleLog#reValidate 才真正校验, 也是读取record的方式 确定 写入位置, 正常情况下不需要读取, 因为 filechannel.size 就是 checkpoint 对应的文件的 offset.
dispatch log
也是基于validator抽象实现, 因为 dispatchLog 存储的是 sequence, 所以可用的文件长度就是 sequence的倍数.
显然, 恢复过程并没有 IterateOffsetManager#iterateOffset 和 messagelog 以及 schedule log 的关系. 比如 message log 比 iteratorOffsetManager#iterateOffset 小的情况. 所以存在误删除 messageLog 文件的情况, 那么 最新添加的消息可能是不会分发的.
主从同步
qmq 的主从同步是自己实现的, 通过 slave 向 master 拉取数据信息. 那么 哪些需要主从同步? message log 和 dispatch log, 为什么没有schedule log, 因为 schedule log 是从 message log 异步构建的, 因此不需要同步.
稳定的到期
qmq 在内存维护了一个时间轮的实现, 投递的消息会先投递到 内存的时间轮以及 文件上, 写入文件是为了避免消息丢失, 写入时间轮是为了保障 延迟消息的及时处理. 时间轮的实现参考 HashedWheelTimer & WheelTickManager.
-
HashedWheelTimer: 使用 HashedWheelBucket 的数组作为 ring, HashedWheelBucket 用双向链表 存储了 HashedWheelTimeout (新增总是添加到tail), HashedWheelTimeout 存储 ScheduleIndex, 到期的时候从 schedule log 加载数据发送出去; remainingRounds 表示几轮, 因为是多轮时间轮的设计, 因此 HashedWheelBucket 的 HashedWheelTimeout 并不是都一起过期的, 需要遍历判断, 对于没有过去的数据, 需要 remainingRounds - 1; deadline字段存储过期的目标时间.
到期的消息发送失败怎么办? 因为发送是先投递到 queue, 如果投递queue失败, 就是不断重试; 投递成功queue, 就 processor处理, 1. RPCQueueSender#process -> MessageSenderGroup#send 2. SenderProcessor#process -> SenderExecutor#execute -> SenderGroup#send
worker: 执行tick逻辑,每次tick 会调用 bucket#expireTimeouts. 会遍历bucket上的所有的 HashedWheelTimeout 执行过期逻辑: 重新投递回实时queue 或者remainingRounds - 1. 当前时间还没有达到 tick 的过期目标时间, 会 sleep (waitForNextTick)
-
WheelTickManager: 负责整个时间轮的实现. 启动的时候, 会从最新的dispatchLog构建未被发送的schedule log 的消息, 并添加到时间轮. 同时也会启动一个定时任务, 根据
config.getLoadSegmentDelayMinutes()每个delayMinute读取相应的schedule log索引到 时间轮. 除此之外, LogIterateService 在读取messagelog的消息, 根据bus机制 也会将消息添加到 wheelTickManager. 相关代码参看:
private boolean iterateCallback(final ScheduleIndex index) {
long scheduleTime = index.getScheduleTime();
long offset = index.getOffset();
if (wheelTickManager.canAdd(scheduleTime, offset)) {
wheelTickManager.addWHeel(index);
return true;
}
return false;
}
在到期消息处理的过程中, 下游投递是一直不断重试的. 可以参看 NettySender 和 SenderProcessor. 这样就不存在消息投递失败的其他异常处理了, 如果是broker出现问题, 这个设计还是优良的.
但是问题也是很明显的, 当下游出现 subject 不合法的话, 重试就变得不合理了. 因为 是将过期消息投递到下游正常broker的指定的subject.
当宕机的情况下, 如果重启, 中间的时间的消息还没有投递出去. 当重启的时候, 除了dispatchLog 会将当时还没有投递的消息重新投递, 在启动定时任务加载 schedule log 的索引的时候, 是加载 (loadedCursor, until) 的所有schedule log. 那么 loadedCursor 是什么赋予了非0值的呢? 是在recover的过程 (根据dispatchlog加载schedule log)
投递方式
qmq整体基于netty实现, 过期消息的发送参考 sender package, 会将到期的消息投递回 普通broker. 需要注意的是, 这里对于投递失败一直是不断重试的. 问题和上面叙述的类似, 消息会投递给 普通broker 的subject.
取消
qmq 的设计实现中, 没有实现延迟消息的取消.
补充
sequence 用的 atomicLong 的设计, 按照设计最大只有 21 亿. 假设1qps, 一年 3_110_400 ~ 300w, 21亿= 21 000 w / 300 w = 70年. 如果是 100qps, 那只能存储 0.7 年, 和去哪儿 2年的设计不符合. 在线上使用 rocketmq 过程中, 一般是 保存2天左右, 特使情况1周, 如果是延迟消息, 因为保存时间很长, sequence 应该重新设计. 建议是 目标时间戳 + sequence 自增.