16 minutes
Mit_6
序
记录学习 mit 6.824 课程的经历
MapReduce 1
目标:
将任务拆解成map 和 reduce 两个阶段, 进行 大规模的数据处理, 比如 页面爬取、词频统计
模型
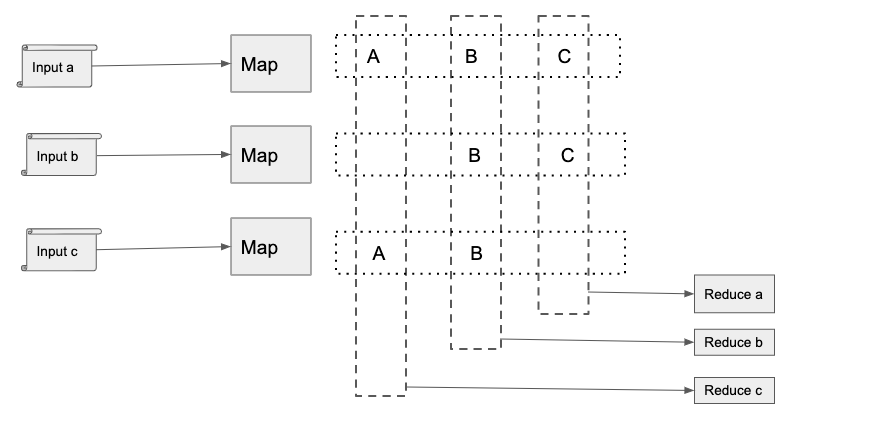
如上图, map/reduce 架构会将用户输入切成若干份数据输入(map的个数), 由map进行处理, 按照论文的说法, map读取文件是本地读取操作, map计算后得到的结果, 会按照 hash到若干份(reduce个数)本地文件存储, 并将存储位置上报给 master, master启动reduce worker, reduce worker会远程获取 每个map机器上的文件, 本地计算后输出到 gfs(分布式文件存储)上. 为了更好的性能和效果, 在map输出后以及reduce输入前, 会有一个combiner任务, 对map的结果进行预处理, 减少网络传输, 但是和reduce不同, combiner 的输出结果是存储在磁盘上的.
分布式场景下, 容易出现一些坏的机器导致map/reduce 执行慢, 对此, map/reduce 架构会重新执行任务. 对于执行完宕机的场景, map会触发重新执行(结果存放在本地), reduce 不需要重新执行(结果存放在gfs)
map/reduce的场景中, 需要处理 热点倾斜的问题, 因为会出现大量数据集中在一台reduce机器上, 对于这种问题, 需要自定义良好的 partition 函数, 将数据尽可能的平均打散
hadoop
架构
将论文中 partition/combiner 的抽象成 shuffle, 进行分区、排序、分割, 将属于同一划分(分区)的输出合并在一起并写在磁盘上,最终得到一个分区有序的文件.
问题
- 难以实时计算(处理存储在磁盘上的离线数据)
- 不能流式计算(处理的数据源是静态的文件, 流式计算处理的数据是动态的, storm/spark)
- 难以 DAG(任务输入和输出依赖的有向无环图, mapreduce的计算结果都会写入磁盘, 会造成大量频繁io, 性能低下, spark)
GFS 2
架构
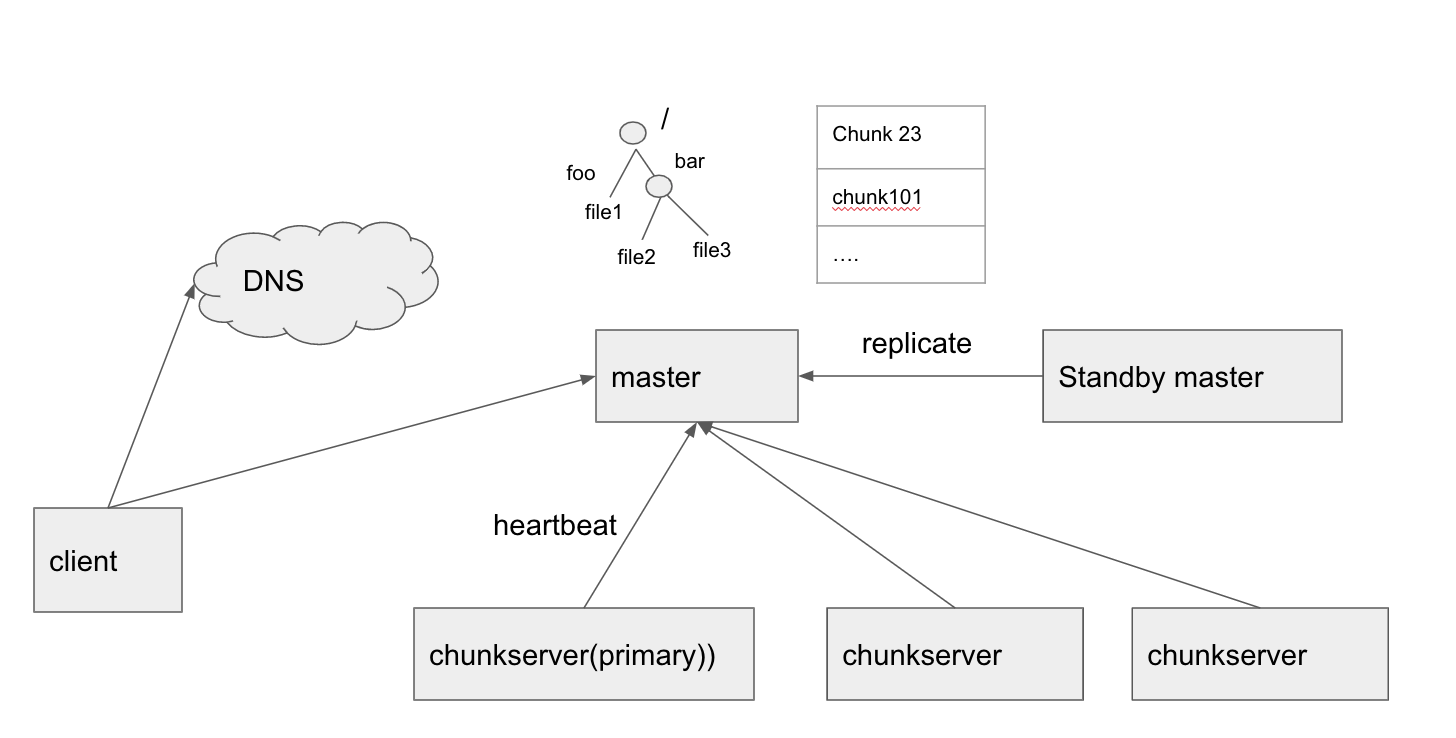
根据论文的描述, 核心组件是 master 和 chunkserver, master 负责管理chunk replica(创建、替换、复制、负载均衡, 通过chunk version number区分最新的chunk)、chunk 选主(lease机制)、GC(通过心跳进行懒删除文件)、文件管理(目录的形式组织文件), chunkserver 负责存储 chunk, chunk是存储的最小单位, 一个文件会被划分成多个chunk, chunk默认是 64MB.
master的数据特点: 通过operation log 记录所有请求操作, 并定期将内存状态存储到checkpoint, 加快恢复时间. chunkserver的数据特点: chunk内部会划分成 64KB 的 block, 每个block做checksum校验, 避免损坏的数据.
在高可用方面, master 也是多副本的, 不过以standby的形式存在, 当master挂了, 通过DNS切换通知客户端. chunkserver本身的多副本机制确保了高可用.
需要注意的是, master 持久化的元数据并不包括 chunk->chunkservers 的映射, 这个是通过master-chunkserver 之间的心跳上报实现的. (rocketmq中topic->brokers的映射也是这样, kafka则将这些信息维护在了zk上)
写入
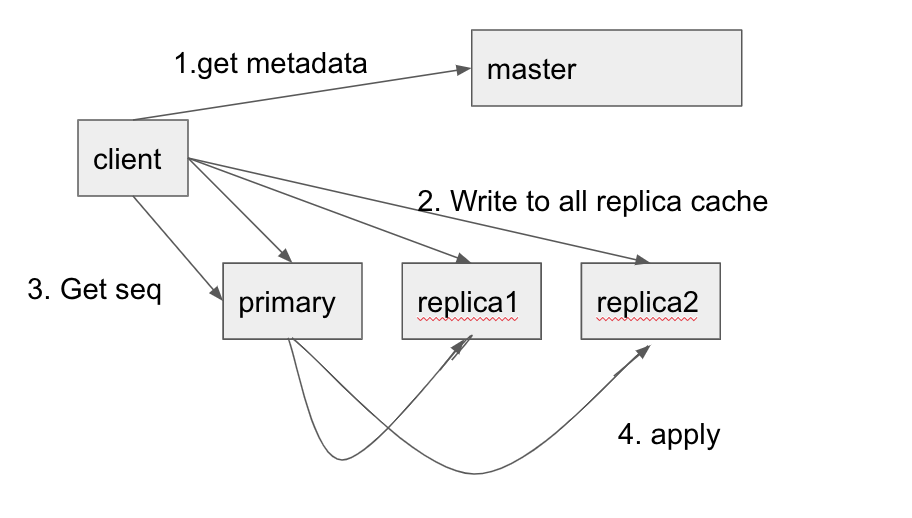
写入比较特殊, 根据论文, 写入其实是个两阶段提交, 如图所示, 首先, 客户端从master获取到元数据(primary+secondary replica)并缓存起来, 然后客户端向所有的chunkserver发送写请求, chunkserver 将请求写入到自己的LRU缓存(注意这里没落盘), 确保全部写入成功后(失败会重试), client 请求primary提交数据, primary 会分配一个连续的序列号, 然后将将之前的修改存储起来, 然后primary请求所有secondary进行落盘, 如果部分replica落盘失败, primary返回错误给client, client会重试保证最终成功避免数据的不一致.
但是我比较疑惑的是, 写入是指写入到指定位置(offset) 还是指定的chunk 吗? append 的语意比较清晰, 就是追加到文件末尾.
append语意比write略微复杂, append 需要保证写入的chunk有足够的空间容纳数据, 否则会对当前chunk进行补齐(primary会同步secondary进行同样的操作), 然后client重试下一个chunk.
gfs并没有支持更新.
需要注意的时候, 数据的一致性完全依赖客户端的重试. 这样选主之后, 即使primary不是最新的, 也可以通过重试补齐. 有些暴力, 因为很多业务并不需要全部成功, 可以容忍失败, 希望尽快的返回错误, 因此现在基本上使用 raft 的方式同步, 但是相比retry, 复杂了些, 而且raft 至少需要三副本.
hdfs
架构
基本上和GFS一致, 抽象了类似的 Namenode 和 Datanode, NameNode 提供文件的操作行为, client读写直接和 Datanode 交互. 将文件的存储划分成多个block, block size 是每个文件配置好的. Namenode 和 Datanode 通过 Heartbeat(节点正常)/Blockreport(上报block) 维护副本, 副本策略? 副本leader(hdfs没有副本leader的概念) 支持副本多机房. 读取的时候, 优先读取本地机房(也就是说, 可能读取的是 follower replica), 如果本地机房有多个, 或者没有本地机房的节点, 又该怎么操作呢? 为了保证启动的时候复制的正确性, 提出了 safemode, 保证只有Namenode在收集到所有的block信息之后, 才决定副本复制. Namenode 使用 EditLog的 transaction log来记录变更, 另外使用叫 FsImage 的文件来记录 文件->blocks的映射, Namenode 也是用 FsImage(相当于checkpoint)+Editlog 重新生成 内存信息(blockMap), 启动操作后, 通常会重新生成一个版本的 FsImage, 为了避免Editlog太大, 启动的时候会进行checkpoint操作截断 transaction log(未来支持周期性的checkpoint). 在Datanode存储上, 因为操作系统对大量文件的目录管理能力弱, 因此会分成多个 目录管理(每个目录会设置最佳数量). 目前hdfs支持的 block size 是 64MB.
在实现上, 比较呕心的是, 文件创建操作并不是立即触发的, 而是在发生真正的block写的时候才会触发Namenode(需要客户端本地攒一波数据满足block才能发送)(当前版本的目录创建貌似是立即产生的). 在后面写入的时候, 也是本地积攒一个block 然后发送到第一个DataNode(每次rpc应该是4kb), 然后第一个Datanode 通过 chain replication/pipeline 的方式复制. 写入成功通过 dfs.replication.min 确定(因为是chain的方式,所以肯定是前面的写入成功), 类似kafka的min.ack参数.
开源有hdfs, hdfs存在以下问题:
- 不适合低延迟数据访问, hdfs 的设计目标是高吞吐量
- 无法存储大量小文件 (参考facebook hystack)
- 不支持多用户写入和随机修改 (hdfs的一个文件只有一个写入者, 并且是追加写)
补充: 小米和头条都基于hdfs做了MQ, 但是MQ本身是面向大文件存储的, 开源的实现还没有实现 appending-write 的功能, 而且 hdfs 要求只有一个writer写入, 一定程度上限制了吞吐量 (其实倒还好, 一个实例仅仅负责转发写入qps还是可以很高的).
参考: https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#Introduction
新版cfs
google 对gfs做了一次升级, 降低master单点故障, 但是思路很神奇, 最终是将元数据存储在chubby+bigtable上. 更多参考
primary-backup 3
根据论文内容, 这个思路是基于虚拟机的, 通过底层 hypervisor进行数据的同步, 如下:
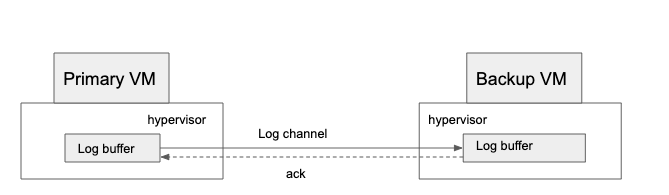
primary会通过 log channel 将数据同步给 backup, backup receive之后primary才会响应给client, 这里存在几个问题:
- logchannel 同步带宽
- backup receive 速度, 太慢影响primary的处理响应, 太快backup来不及处理导致lag增大(这样backup成为leader后, 需要先消费完这些数据才能成为leader, 灾备时间被延迟了)
- 非确定性的事件太多, 因为是机器级别的复制, 存在计时等干扰的非确定性因素同步
- 引入了 共享磁盘/非共享磁盘的 复杂度. 磁盘用来脑裂
- 存在重复输出和丢失输出(告诉客户端存在, 实际上backup并没与同步到)
参考
raft 4
以可理解性为目标, 解耦了 leader election、log replication、safety 三个方面, 如下:
- strong leader: 写从leader流向 follower
- leader election: 随机timer
- membership change: joint consensus/ 联合一致性
基于 有序的replicated log 的复制状态机(replicated state machine). 一致性模块 确保 replicated log的一致性. 安全(非拜占庭问题下)、可用、不依赖时间. 更多的参考之前的学习: paper
在实践上, 建议参考 5
进一步阅读: Oki and Liskov’s Viewstamped Replication [29, 22] chubby spanner
zookeeper 6
目标: 提供构建复杂协调原语的简单、高性能的内核
这里的论文6 只是讲述了 zookeeper基于zab构建的协调服务. 对外提供的语意: lock,read/write lock, double barier, leader election, group membership, configuraiton management, zookeeper 抽象了znode存储数据(最大1MB), 参照 文件系统的 层级结构 组织znode. 并提供了 Regular 和 Ephemeral 两种 znode. 文章中重点讲述了 zookeeper 对外的 client api: create/delete/exists/get/getdata/setdata/getChildren/sync, 其中, getData、exits、getChildren 提供了 watch 模式, 用于当数据变更的时候进行通知, 但是需要注意的是, 数据获取的这几种方式并不是连接leader获取最新的数据, 默认是获取任意server本地的数据, 这样虽然提供了并发性能, 但是存在”stale data“/过期数据的问题, 支持如果想获取最新数据, zookeeper 提供了 sync 的api, 在调用read之前调用sync, sync会保证将之前pending write执行完, 这样再read就是最新的数据了. 按照论文的说法, sync+leader 应该是在leader上的, 根据读操作 FIFO 的特性, sync就不需要 zab原子广播, 只需要本地前面的操作同步完就可以了, 但是需要确保leader还持有租约, zookeeper 的解决方案比较直接, 通过前一个zab广播协议进行leader确认, 如果不是leader的话广播就会失败, 这里存在一个特别点, 如果sync+read之前有写操作, 直接依赖之前的写操作的广播协议, 如果没有写操作, 则需要一个 null transaction的原子广播执行.
这里谈到了读操作, 其实zookeeper提供的操作是 线性写、FIFO read, 线性写必须是通过leader执行, 通过zab原子广播到其他节点, 因此节点越多写操作越慢. 在内部存储上, zookeeper 用内存存储状态, replay log(wal) 存储提交的操作, 并且周期性的生成快照. 在快照这一块, zookeeper 并没有使用锁, 而是深度遍历生成快照, 也就意味着快照内数据的时间点是不一致的, 但是因为数据的状态改变是幂等的, 因此可以重复apply.
和之前的论文不同的地方是, 这篇论文还重点举例了 zookeeper的几个应用: fetching service、indexer service、message broker.
奇怪的是, 这篇文章并没有讲述 zab 协议的具体细节.
异步 线性 zookeeper
https://www.cnblogs.com/yeyang/p/11420920.html chubby 有论文吗?
其他参考阅读(TODO):
- zab 论文: http://dl.acm.org/citation.cfm?id=2056409 或者 https://github.com/jayknoxqu/pasox_zab_protocol/blob/master/2012-deSouzaMedeiros.pdf 和 https://distributedalgorithm.wordpress.com/2015/06/20/architecture-of-zab-zookeeper-atomic-broadcast-protocol/
- 线性和时序: http://www.bailis.org/blog/linearizability-versus-serializability/
- wait-free定义参考: https://cs.brown.edu/~mph/Herlihy91/p124-herlihy.pdf
- zk集群动态配置: https://zookeeper.apache.org/doc/r3.5.3-beta/zookeeperReconfig.html
- zk集群动态配置: https://www.usenix.org/system/files/conference/atc12/atc12-final74.pdf
- zab 和 paxos 的思考: https://cwiki.apache.org/confluence/display/ZOOKEEPER/Zab+vs.+Paxos
CRAQ7
对象存储的范畴, 架构参考:
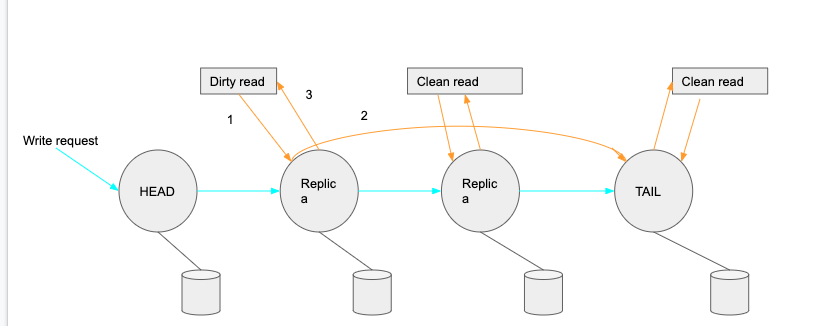
全称是: Chain Replication with Apportioned Queries: 分摊查询的级联复制, 相比CR, 通过分摊查询压力到其他节点提升了整个架构的读吞吐量. 传统的CR模型, head负责write, tail负责read, 写入从head不断下沉到tail, tail 是整个commit的保证, tail commit之后逐级反馈到head, 然后head发送响应到client. 因为tail 是最终commit的保证, 因此从tail读取肯定是已经提交的最新的数据. 那么 CRAQ 模型将读取压力分摊到其他节点, 怎么保证读取的是最新的数据呢? 根据初始的CQ模型, write是级联下沉的, 当节点收到write但是还没收到commit, 那么就会标记数据为 dirty, 当client read定向到这个节点, 这个节点会请求 tail 节点获取最新的数据, 然后相应给客户端; 如果被请求的节点没有标记dirty, 那么节点直接返回数据. 这样就避免了stale read.
适配全球化进程, craq 还支持了 多数据中心、多Chain, 但是和raft不一样, 本身不解决协调问题, 而是依赖zk解决 group membership(成员管理)、元数据存储、以及节点变更通知. 但是论文并没有讨论相关细节. 论文中还谈到了 广播协议, 避免逐级传播的网络开销, 加快write和commit流程. 比较遗憾的是, 论文中提到 大对象的原子更新用小事务完成, 不过没有完成. 在节点变更上, 略微有些复杂, 甚至有些地方不是很理解, 实现的话需要认真思考下
在功能上, 除了 对象存储常规的 read/write, 还支持 prepend/append、incre/decr、test-and.
在压测结果上, 整个效果还是很理想的.
AURORA 8
mysql/postgresql兼容的关系型数据库. 参考论文中的良心架构:
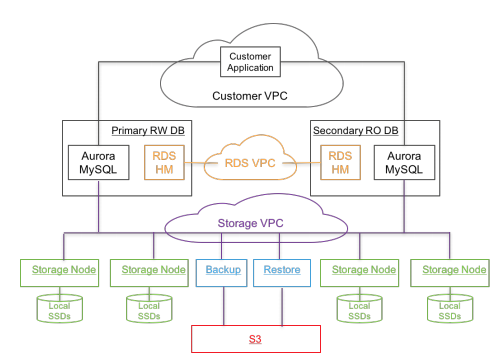
aurora 是 amazon 提供的 OLAP关系型数据库, 在mysql 5.6 分支上改造, 将存储层和计算层进行了分离. aurora 重点在于 the log is the database, 通过同步虚拟分段的redo log 进行存储层之间的数据同步, 减少mysql mirror模型下大量的数据同步, 需要注意的是, aurora 用的是6路复制(3个az, 每个az两个副本). 在一致性层面, 通过quorum达成了最终一致性, 并通过 gossip 进行数据的补齐. 本质上是个 一写多读 的方案. 比较特别的是, 还用了s3做备份
在架构上, 计算层是 Aurora MySQL/instance, 存储层是 Storage Node. 在工程实践上, 计算层只是简单的 fork 了 mysql源码并简单了修改.
分层的设计中, instance(database tire)负责: query processor, transactions, locking, buffer cache, access methods and undo management; storage node负责: redo logging, durable storage, crash recovery, and backup/restore. 也就是将存储层进行了沉降.
写入流程: storage node将接受到的 redo log record(这个是个啥?)添加到内存队列, 持久化到磁盘上后ack. 在apply的时候, 会检查是否存在lag, 如果存在lag, 则通过gossip协议进行补齐. 最终将记录放到新的数据页, 并周期性同步到s3, 并周期性的 gc老版本 和 校验 crc. 这里只有内存队列排队和ack 两个步骤是同步的, 其他是异步的, 所以性能会有所提升. 可以明显的发现, 这里调用写入和写入page其实是两个分离的行为, 那么是否存在着 客户端写入被ack了, 但是读取的时候可能读取到的是 stale data/过期的数据.
读流程: 根据分层设计, instance(database layer) 负责 buffer cache, 因此读取大部分情况下是读取 database layer, 只有当数据页找不到的时候, 才会产生 storage IO 请求. 因此缓存数据, 所以存在空间不够需要驱逐的场景, 传统数据库是刷新dirty page, 但是在 aurora, 则是刷新 PAGE LSN 大于vdl的page, 因为读取都是读取当前vdl的数据, 因此大于vdl的数据则是没有意义的. 问题, 如果都是小于等于vdl的, 怎么驱逐呢? 在read的时候, 使用 vdl 取代了读取快照作为 read point, 而不是通过read quorom来达成一致, database layer 是知道每个 segment 的 scl, 但是需要处理 segment 不能给出大于 read point的数据, 除此之外, database 可以计算出 Protection Group Min Read Point LSN(PGMRPL), 也就是read 请求的 read point 不可能小于 PGMRPL, 通过这个点, storage node 可以安全的回收
关于复制, 在传统的镜像复制/mysql mirror中, Primary/Backup Instance 之间复制需要 Log、Binlog、Data、FRMFiles(元数据), aurora 只需要同步 redo log 就可以了.
分段的设计中, database volumn 被分成 固定大小的(10GB)的 segment, 通过复制构成 pg(protection groups), 通过分段减少 mttr(平均恢复时间), 因为 mttf 是不可控制的.
更艳遇事务, 多个事务之间的干扰处理 以及 事务处理没怎么说. 但是只有一个 writer, 模型应该相对简单
对于恢复的处理, 常规的wal+快照, 同时也有undo log回滚未提交的日志. 也会增加一个 epoch 避免崩溃恢复被打断. 除此之外, instance(database layer) 需要重新构建运行时状态, 比如数据缓冲和一些元数据(vdl). 对于undo, aurora因为设计在database层, 所以 database 进行执行.
几个概念:
- LSN: 日志序列号, 每个日志记录的唯一ID
- SCL/Segment Complete LSN: segment PG已经收到的最大的LSN. 用来gossip阶段数据补齐的. 每个storage node 不一样. 读取的时候, 需要选择 scl > read point 的.
- VCL/Volumn Complete LSN: 存储层上之前的日志记录的"可用”, 在恢复期间, 大于VCL的日志记录都会被截断. 在恢复期间, storage server 上 已经被 quorum reads 存储的最大的LSN. 可能还未提交. Storage layer的概念
- CPL/Cosistemcy Point LSN: database layer 的概念. 每个mtrs(mini transaction, 每个database layer的transaction会被分成多个mini transaction)产生的最后一个log record的LSN.
- VDL/Volumn Durable LSN: database layer的概念. 最大的CPL. 恢复阶段通过read quorum确定. 小于 VCL. write流程中, database layer 收到 storage layer的ack的时候, 就会增长
恢复的时候, database 和 storage沟通 创建每个pg的 durable point来创建 vdl.
几个问题:
- mysql mirror 的模型: 暂时没找到资料, 论文中说 需要同步binlog redolog data 和 double write, 按照之前的经验, 我们使用的binlog同步复制策略并没与这么多数据需要同步. 不是很理解
- redo log: 记录页的变更记录, innodb 的wal. 因此 ddl 变更 对应的redo log也是很大的
- 看样子底层存储使用的是 amazon block store,这个不就有一致性能力吗? 为什么还需要复制?
- 事务的处理: ? 仅仅说了在 database layer将事务拆分成多个 mtrs, 最终commit
- 事务隔离级别的保证: 支持可重复读
- quorum需要保证写入失败的场景下, 通过gossip不会写入所有副本, 不然冗余数据被提交了呀.
- storage tier 负责生成数据页, 那么有个问题, database tire/instance 没有数据有怎么生成 redo log 呢? 因此是 database layer 会从 storage node 捞取数据上去, 并且只有在 vdl
- 读取空间不足, 如果都是 page lsn <= vdl, evit alg 怎么实践?
- 存在写入成功后, 不一定立即能够读取到, 因为ack 是先写入wal的, storage node可能还没有处理, 怎么解决的?
更多参考:
- https://www.percona.com/blog/2015/11/16/amazon-aurora-looking-deeper/
- http://www.yunweipai.com/archives/18411.html
Frangipani 9
Frangipani 是基于分层的文件系统设计, 底层存储使用是 Petal的分布式虚拟磁盘服务, 多个 Frangipani 共享底层 petal, 使用 petal 提供的 锁服务 来获取存储, petal 提供的存储也是基于 block 的, 和常规的存储不一样的地方, petal 的存储是非常大的, 有 2^64 的地址空间, 空间分配也是TB级别的.
log
Frangipani 在 petal 开辟了一段空间存放 wal, 用来记录元数据变更, 但是需要注意的是, 变更数据一开始是存放在 Frangipani 内存中的, 然后 周期性同步到 petal 上, 这就意味着如果在 同步到petal之前挂了, 这部分数据也就丢失了. log 设计是两个 64KB 的环形buffer, 只有在apply之后才能从buffer中删除
缓存一致性&lock service
因为是 Frangipani 共享操作 petal 上的数据, 因此需要保证 每个 Frangipani 的数据一致性, Frangipani 使用了 multiple-reader/single-writer lock 来实现同步, writer 的dirty data 在锁冲突的情况下也需要刷回磁盘. 需要注意的是 Frangipani server 互相之间是不通信的, 而是采用数据共享. 除此之外, Frangipani 的锁只有在冲突的时候才会被释放, 因此一定程度上是sticky的, 为了解决 lock holder崩溃的场景, 使用了 lease 概念, 通过续租来长时间持有锁. petal 内部使用 paxos进行数据同步, lock service 也基于内部的 paxos 同步数据. Frangipani 内部将 lock 拆成了多个 lock group 达成更高的效率. 为了避免过期租约的写入, 使用了 时间比较的措施, 拒绝低于当前时间的写入.
问题:
分层的设计中, 缓存只是重点讲了缓存一致性, 并没有讨论缓存的设计.
更多petal 的资料可以参考: http://www.scs.stanford.edu/nyu/02fa/sched/petal.pdf
spanner10
google spanner 定位可扩展、多版本、全球分布、同步复制的数据库.
在数据模型上, spanner 支持的sql table, 但是对应的底层是 kv模型, spanner中称之为 tablet, 表示如 (key:string, timestamp:int64) → string. 其中, 通过 timestamp 支持了 多版本和事务的能力. spanner 还将相同前缀的key 抽象成 directory, 通过 分片将 directory 切分成多个 fragments, 不同的fragments可以分布在不同的 paxos group 上. 但是在paxos group中数据移动的单位却是 directory, (感觉应该是gragment).
在存储上, 底层使用了 Colossus(gfs的后续替代版本) 存储了 tablet 的状态(B-tree) 和 wal. 比较有意思的是, 这里的日志需要写两次, 一次写 tablet log, 一次写 paxos log.
在一致性层面上, 使用 single-paxos state machine 实现 一致性复制, 每个副本的kv状态映射. paxos leader 还基于 lock table(部分key->state) 实现了并发控制. 事务的实现中, 也是基于 paxos-leader 的参与实现的
spanner 的版本和事务都依赖 自己提供的 TrueTime api, 保证了 时间的单调性. 底层实现基于 GPS 和 原子钟(石英) 两种模式, 以便灾备: GPS有天线&接受失败、本地频道干扰, 原子时钟会有时钟漂移的问题. 在实现上, 每个机房会部署 一组 time master, 每个集群上会部署 timeslave 后台进程, 大部分 time master 会 配置 GPS 并分散部署, 其他master配置石英钟, 彼此检查确保时间的准确性. 每个机器的后台进程 会拉取很多master并通过 Marzullo’s algorithm网络时间协议进行校准.
spanner对外提供的操作: readwrite transactions, read-only transactions(snapshot-isolation transactions), snapshot reads. 写事务 在spanner中等价于 readwrite transactions. ps: 这些操作都是内部不断重试的.
- 快照读本质上是读过去, 客户端可以提供一个时间戳, 或者提供一个上界(让系统选择一个时间), 快照读可以在任意一个最新的副本上执行.
- read-only transaction 不需要加锁, 按照系统选择的时间执行, 因此写入不会受到阻塞, 并且可以在任意一个最新的副本上执行. 这里需要注意一个问题, 系统选择的时间: 如果读取事务只涉及到一个 group, 则直接使用 paxos last commited write timestamp, 如果涉及到多个group, 直接使用 TT.now().latest (会导致等待保证时间对齐)
- 读写事务 最复杂, 需要两阶段锁,
- 读取的时候会向相应group leader获取读锁 并读取最近的数据, 为了避免读取导致事务超时, client会向leader发送keepalive消息,
- client本地修改后, 选取一个group 作为 coordinator group
- client 将coordinator group identity 以及 缓存的数据发送给 participant leader
- non-coordinator-participant leader 获取写锁 并 选择一个 prepare timestamp (比之前的事务大) 并通过paxos同步 prepare record
- coordinator leader 也会获取 写锁, 但是跳过了 prepare record, 在收到 participant leaders 的响应后, 选择一个 commit timestamp (大于所有的prepare timestamp, 大于接受请求的时间, 大于之前事务的时间; 为了保证单调性, 会等待时间成为过去) 并通过paxos同步 commit record
- coordinator 发送 commit timestamp 给client 和 其他 participant leaders, participant leaders 通过paxos同步事务结果, 并释放锁
spanner 还支持了 schema change的事务, 但是是非阻塞的, spanner schema change 是面向未来的, 不是立即发生, 只是注册在prepared截断(是因为), 只有在读写触发的时候才执行?
在部署模型上, 一个spanner部署单元是一个 universe, 比如测开一个, 生产一个. 一个universe由多个zone组合, 每个zone都是一个管理单元, 一个datacenter有一个或者多个zone, zone内部有多个spanner server(负责存储数据)、location proxies(client用来定位数据提供的spanner server)、zonemaster(负责分配数据给spanner server). 每个universe 有 placement diver (负责数据迁移) 和 universe master (展示运行时信息的console).
问题:
- schema change 的非阻塞的具体是指? 是指读写触发才会阻塞, 触发schema变动的行为?
其他:
Marzullo’s algorithm: 参考https://www.wikiwand.com/zh-cn/%E7%B6%B2%E8%B7%AF%E6%99%82%E9%96%93%E5%8D%94%E5%AE%9A
FaRM 11
定位数据库, 但是通过 RDMA、DRAM 达到了一致性和高可用. 常规数据库因为需要复制等一致性相关操作无法达成很高的性能, FaRM 基于 RDMA(Remote Direct Memory Access) 实现数据传输的kernel bypass, 避免频繁cpu中断带来的耗时. 数据先写入DRAM, 然后通过UPS支持, 将 NVDRAM 的数据写回磁盘, 保证性能和可用.
在 DRAM 的使用上, 用2GB的 region划分了全局地址空间, 每个region都有一个primary和多个backup(f是配置的容错), 每台机器上有多个region, 在读取的时候, 总是读取 primary(本地获取或者RDMA), region的分布情况在CM管理. 有意义的是, 为了保证region->replica 的有效性, CM 使用了两阶段提交协议, cm发送prepare消息给指定副本来保证副本有region分配, 然后CM在发送commit消息.
FaRM 使用 vertical Paxos 进行 coordinator 和数据复制. 在事务的处理上, FaRM 采用了乐观并发控制的4阶段协议:
- lock: coordinator 写一个 lock reord 给被修改对象的 primary(版本、新的值、以及region), primary通过cas进行版本锁定, 任意一个失败就都失败了. 失败场景下, coordinator 会写一个 abort record 给所有primary
- validation: coordinator执行读取操作进行读验证 (个人问题: 既然已经lock了, 为什么要validation?)
- commit backup: 给backup发送 COMMIT-BACKUP record 并等待ack (写入non-volatile logs)
- commit primary: coordinator 收到ack之后, 写 COMMITPRIMARY record 给各个primary, primary 就地更细对象, 增加版本号, 释放锁.
并发控制上, 每个对象都有一个 64bit 的版本用来并发控制.
因为使用了RDMA, 无法支持lease机制(是因为定时功能所以无法使用?), 因此提出了 precise membership 来确保各个机器之间的配置统一. 在 失败发生的时候, 就会触发一个新的配置, 所有的机器需要对成员达成一致, reconfigure 流程如下:
- Suspect: 1. 机器租约过期, CM 会初始化 re-configure 2. 机器怀疑cm租约过期, 机器会请求一个cm备机(一致性hash的第k个后继?)来初始化配置. 如果配置没有变化, (n it attempts the reconfiguration itself)?? 不懂
- Probe: 新的CM会请求RDMA 读取各个正常的机器, 只有大部分实例响应了, 新的CM才能继续处理reconfigure
- Update configuration: 新的CM通过 znode seq number cas 升级到新的配置, 存储到zk
- Remap regions: remap来保证region replica是 f+1, paimary失败的场景使用, 提升一个backup
- Send new configuration: CM同步配置给所有机器. 如果CM变更了, 还会重置lease协议
- Apply new configuration: 机器执行新的配置, 拒绝来自其他机器的不属于自己region的请求, 并阻塞外部客户端的请求
- Commit new configuration: CM收到所有机器的 NEW-CONFIG-ACK 消息后, 等待 offline机器的租约过期, 然后发送 NEW-CONFIGCOMMIT 作为租约授权. 这个时候, 各个机器才会接触对client的阻塞, 并且 开始事务恢复.
在事务恢复处理上, FaRM 只会阻塞受影响事务的处理(需要恢复), 对于不需要恢复的事务是可以并发处理的. 在失败检测方便,利用高速网络进行频繁的心跳进行失败检测, 同时利用 priorities 和 pre-allocation防止误判 (论文中却没有展开)
整体而言, 事务的恢复也很复杂, 流程如下:
- Block access to recovering regions: 当recovering region 的primary挂了, 我们需要阻塞region的获取, 知道新的primary拿到了所有更新region的write lock
- Drain logs: 配置变更的事务场景下, nic 是不关心configuraiton, 直接ack COMMIT-BACKUP and COMMIT-PRIMARY records(cordinator会等待ack), 因此在收到新的配置, 通过
draining logs来处理相关的日志. (那是不是可以修改ack实现感知到new configuraiton) - Find recovering transactions: 如何判断是recovering transaction? primary/backup/coodinator 需要在 c-1,c 变化了, 但是transaction在c-1中正在提交.
- Lock recovery: 并行多线程操作恢复, 被 recovering transaction修改的 对象会被锁住.
- Replicate log records: primary向replica发送 REPLICATE-TXSTATE 补齐事务
- Vote: coordinator 判断是否提交. 取决于region的primary.
- Decide: coordinator 判断是否提交.
整体而言, 还是比较复杂的.
其他数据恢复: 副本恢复在正常服务后进行.
在配置管理上, 使用zookeeper进行存储和配置达成一致, 但是在 租约管理、失败检测、coordinate恢复并不依赖 zookeeper. CM 仅仅在 配置更新的时候调用zk.
问题: cm 是如何选出来的?
spark 12
通过RDD抽象, 将数据在内存中操作, 极大的提升了性能, 解决了 迭代算法 和 交互式数据挖掘的 性能问题. RDD 相比于其他共享内存方案, 在于提供了 transformation 的语意, 而不是 update, transformation 的特点在于 操作生成新的RDD 而不是 修改现有的 RDD, 目前支持的 transformation 有 map filter flatMap sample groupByKey reduceByKey union join cogroup crossGroup mapValues sort partitionBy. 对于多个RDD之间的依赖, 提供了 wide dependencies 和 narrow dependencies, 从自己的理解的角度, narrow dependencies 是两层RDD 一对一, wide dependencies 是两层 多对多, 也就是 第一级 RDD 产生的结果是否需要传输到其他节点, 一对一是不需要传递的, 因此可以做到 单节点 pipeline 的效果, 减少了 序列化/反序列化 和 网络传输的 开销.
在用户体验方面, 通过 Class shipping 和 Modified code generation 实现了高级编译器. 内存管理方面, 不仅仅支持内存存储序列化/反序列化的结果, 也支持磁盘存储. 在失败恢复场景, 除了 narrow dependencies 提供了 血缘重计算减少存储开销(直接重新计算就可以了), wide dependencies 还支持 checkpoint 到稳定的存储中.
spark各种场景兼容了map-reduce的场景, 并且性能对比高出了好几倍.
在后来的引进中, 引入了 dataFrame 的设计, 支持对内存的数据进行解析, 支持 Avro, CSV, elastic search, and Cassandra 等,再后来有使用 dataSet 取代了 dataFrame, 不仅仅继承了 dataFrame 的优点, 还支持了 自定义对象存储 (dataFrame仅支持row对象), 而且类型安全 (如何实现的呢?)
参考: - https://www.zhihu.com/question/48684460
fb memcache 13
架构:
参考 Figure2, 添加 master、salve region/mcrouter/fronted cluster(memcache)/storage
主要将接了 facebook 大规模使用memcache 构建了分布式kv存储, 并从单个集群 演化成 地理分布式集群. facebook 对 memcache 的使用是 cache-aside 模型的, 也就是 先读cache, miss则读取storage(look-aside); write 先操作 数据库, 然后操作cache. 在整体架构上, 最大粒度是 region, 每个region 内有多个集群, 每个集群由 mysql/memcache/mcrouter 构成, 令我惊讶的是, 因为mysql 是 master/salve replication 模型, 因此 架构上对应了 master/slave region. 不理解 cluster 和 region 抽象了意义 ? 补充: region是为了 地理位置的安全性. cluster 只是多服务器的运维单位粒度统称
在region内, 多个集群(web+mcrouter+memcached=multiple frontend clusters) 共享了一套底层存储, 使用 mcsqueal 同步删除的刷新(通过批量降低请求率), 但是更新操作呢? 不然可能存储旧值. 对于新的cluster上线, cold cluster 会请求 warm cluster 避免请求回源(使用2s避免 cold cluster delete 但是warm cluster没有删除的场景?). 对于master/slave region, 对于 master/slave 复制lag的场景, 使用 remote marker 来度量 master/slave 的lag, 每次set/delete操作, 都会在region内生成一个相应key的 remote mark, 后续请求就会检查 remote mark在做决定. 但是并没有解决因为lag导致 读取replicated region 的 stale data的问题.
在使用上, 为了适配不同的使用场景, 比如 读多(容忍过期)、不频繁获取(cache miss昂贵), 将集群的memcached server 换分成多个 pool, 其中, 有一个default/wildcard pool, 其他根据场景在划分, 比如 small pool 和 large pool. 除此之外, 还设计了 memcached replicate 机制(没说怎么复制), 增强处理能力(上层mrouter怎么知道请求其他的replicated memcached实例). 在面向失败的设计原则(少量机器网络不可达、大范围断电), 采用了 Gutter pool, 当client请求没有响应, client就会请求 Gutter pool, 如果未命中, client在请求数据库后就会插入gutter pool, 降低对数据库的压力. 对于 regional 级别的数据(不止一个fronted cluster), 使用 regional pool的 memcached server存储(按道理应该都是 key hash之类的, 那么什么时候走regional pool?).
在使用上优化, 使用 UDP 进行get 请求降低延迟, 因为 get 本身存在一定比例的失败. set/delete 还是TCP. 除此之外, 通过 mcrouter 降低memcache的TCP连接数, 简化滚动升级的影响. 并基于DAG的依赖实现 并行、批量的请求, 平均下来可以有每个请求包含24个key, 减少了请求数. 为了避免网络堵塞, 使用了 滑动窗口 控制client 并发的请求数 (window size太小, 请求轮次太多, 延迟会增加; window size太大, 因为并发量太大、网络阻塞, memcache会返回失败, client需要请求数据库导致延迟增加).
memcache 提供了 set/get/delete 的三种语意, 在大规模、不同场景的使用中进行了优化. 对于set, 存在 stale set 和 thundering herds, stale set, (两次write, 前一次write最后更新了memcache). fb 提供了 lease机制, memcached miss的时候 memcached 会返回一个 lease token 在set的时候进行校验. 同样, 对于 thundering herds, 频繁读取的key被刷新会导致后续大量的set, memcached 对于每个key返回一个10s过期的token, 对于相同key的miss, 其他的client会进行等待一段时间, 这样前面获取lease的client的set之后, 其他client重试就可以获得数据. 对于过期性质的数据, 使用 Transient Item Cache(环形buffer) 降低内存开销.
对于 get, 比较有意思的是, 支持 stale read, 在delete的时候缓存被删除的元素(后面flush会删除), app可以使用stale value而不是等待最新值.
滚动升级的优化, 将数据存放在 System V shared memory regions 确保memcached重启之后数据都会在(但是存在一些stale data)
问题:
- cluster 和 region 抽象了意义 ? 看样子是, a single storage cluster + mutli fronted cluster = region. 为了地理位置容灾
- 什么时候走regional pool
- 更新是否应该同步?
个人想法:
- 对于大量不存在的key, 应该也要存储, 避免大量不存在的请求打垮数据库
- 更新应该也同步
其他需要整理的内容:
- slab改进, 和 linux 的slab 有什么差异? 深入
COPS 14
提供了 causal+ consistency 的kv存储. 核心在于 提供了依赖关系存储, client 在put有依赖关系的kv的时候, storage 除了存储kv, 还会存储 k 的依赖版本信息, 这样在 get_Trans 获取一致性视图的时候, 可以根据依赖的版本, 通过两轮rpc 保证获取数据的因果一致性. 举个论文例子: Alice 更改了相册的ACL: friends only, 然后增加了一些照片. 传统的get操作, 存在 ACL: public 的时候获取了 frends-only 的照片, 因为 time-of-check-to-time-of-use 的时间不一致. 而在 get_Trans 中, 第一轮 get_by_version 获取最新的版本的数据, 第二轮 get_by_version 获取修正后的依赖的版本. 比如 第一轮获取了 ACL: public 和 最新的照片, 那么在第二轮, 会重新获取 最新版本的 ACL: friends only, 这样在本地的数据就是正确的了. 但是维护key的多版本数据会导致存储空间紧张, 因此需要进行GC操作.
在kv的分布式设计上, 每个集群 都有完整kv copy/副本, 每个集群内, keyspace 通过一致性hash的方式存储在相应的节点上. 在容错的设计上, 通过 chain replication 进行复制, 需要注意的是, 这里的复制是跨集群的, 而不是本集群的复制, 并且复制是异步的, 所有的操作(put/)都是 写到本地, 然后异步复制给远端集群.
在冲突的设计上, 默认是 lww, 也可以运行自己编写程序解决.
在设计的接口上, put_after/get_by_version/get_trans, 针对是否使用 get_trans 将系统划分成了 COPS和 COPS-GT版本. 比较有意思的点, 所有的操作 都有一个 ctx 参数, 是用来处理依赖的, 根据依赖的溯源划分成了 Nearest Deps 和 All Deps. put_after 的接口: hbool,versi ← put after (key, val, [deps], nearest, vers=∅), 后面的参数是客户端根据(dep/nearest), vers在put_after中不需要提交, 提交成功后由节点返回. 版本数 使用 Lamport timestamp(高位) + unique node identifier(低位). 服务端会检查 依赖依赖的版本, 如果依赖的版本没有提交, 则会阻塞, 通常客户端已经实现了保证. get_by_version 可以获取 指定版本的数据. get_trans 可以保证多个key的事务的一致性, 但是, 因为 put_after 可能失败, 会导致 部分数据A最新, 依赖他的数据B (A -> B)没有最新, 那么存在一些冗余数据A, 因为没人使用, 如果事务比较复杂, 存在 C -> A, 但是这次 put_after 只操作了 A、B, 那么 get_trans 的语意会遭到破坏 (每次写都需要因果关系的完整性).
论文中特地展开了一致性的讨论,
Linearizability > Sequential > Causal+
> Causal > FIFO
> Per-Key Sequential > Eventual
-
strict (严格的一致性):
-
Linearizability(线性一致性): 1. 任何读操作都能读取到最新的修改 2. 所有操作的时序与真实物理时间一致 3. 时序不确定的并发操作, 在所有线程最终看到的执行序列是一致的. 这里对多个进程/线程 的执行顺序都需要全局有序
-
sequential consistency(顺序一致性): 1. 单个线程的操作的顺序保留 2. 多个线程/进程/节点 执行的事件的先后顺序与物理时钟顺序不保证. 3. 每个进程读到的该数据的不同值的顺序是一致的. 通常采用了 分布式逻辑时钟(lamport时钟) 设置顺序关系
-
Causal Consistency(因果一致性): 1. 具有因果关系的满足 顺序一致性 2. 不相关操作不需要有序
-
FIFO: 1. 同一进程内的多个操作有序 fifo 2. 不同进程无序. 因果一致性 跨域了多个进程, 单机的 因果一致性 就是 fifo.
除了数据一致性, 还有客户端一致性:
- 单调读一致性: 进程对a执行的任何后续读操作总是得到第一次读取的那个值或更新的值 (强调读最新)
- 单调写一致性: 进程对数据项a执行的写操作必须在该进程对a执行任何后续写操作前完成 (强调先来先完成)
- 写后读一致性: 进程对数据项a执行一次写操作的结果总是会被该进程对a执行的后续读操作看见 (强调写操作的可见, 完成不代表可见)
- 读后写一致性: 程对数据项a执行的读操作之后的写操作,保证发生在于a读取值相同或比其更新的值上 (强调最新值上的操作)
而论文中定义了 Causal+, 是 causal consistency + convergent conflict handling.
论文中还提到了ALPS系统的定义: avalibility、Low Latency、partition-tolerate 、high scalability 的 system.
certificate Transparency
这个是阅读相关材料, 并没有论文.
先说下中间人攻击, 可以将DNS域名替换成自己的服务器地址, 模拟一个类似的页面让用户填写用户名和密码, 这个时候隐私就被泄露了.
因此引入了证书&ca、https机制, 证书存储了 DNS-> public key 的映射, ca 包括: DNS name、 public key of that server 、identity of CA、signature with CA’s private key (主要是client验证证书是否被篡改过, browser有ca的公钥, 可以解密出私钥加密的摘要信息, 本地重新对证书摘要计算hash, 常见的是 sha256, 如果一致则没有篡改过), 注意: 浏览器会包含一些可接受ca的公钥. 证书主要是 https 的流程使用, https=http+ssl/tls, 现在基本上使用 tls, ssl 存在问题不再使用. 本质上是通过非对称加解密 协商后续加密使用的 对称加密的秘钥, 在非对称 加解密之前还存在协商的过程. 整体描述如下:
- TCP连接建立之后, client 发送 ClientHello: 客户端支持的 ssl/tls 版本、加密套件、sessionid(复用)、client-random
- server 响应client 返回 ServerHello: 确认的 ssl/tls 版本、加密套件、sessionId、server random、安全证书(含有服务端公钥)
- client 验证server的证书, 并产生随机数 pre-master, 通过 证书的公钥加密后传递给 server
- server 使用服务端私钥 解出 pre-master, 并根据 client-random、server-random、pre-master 产生对称秘钥 master secrect
- client 使用相同的方式产生 对称秘钥 master secrect
- 完成 client 和 server 的交互. 分别发送 client 和 server 的消息
- 使用对称秘钥传输消息
可以发现 第二步和第三步 设计到了 证书的传递和校验, 证书的合法性 是后续协商的重要前提.
在这种场景下, 中间人的攻击会更加困难, 需要提供一个合法证书.
那么, 为什么证书并没有完美的解决这个问题? 首先 DNS 域名的拥有者 难以确认, 任意ca 也可以颁发证书, 公司雇员的恶意注入伪造的ca.
因此, 最直接的解决方式是 做一个证书的数据库, 那么谁来运行这个DB呢?如果支持替换证书, 那么一个域名就会有第二个证书(我其实看不出有什么问题…).
这里提出的 CT 系统, 本质上就是个 审计系统, 并不能立即解决这个问题, 而是及时检测发现. 在CT的组件中, 有 Monitor、Auditor、Log Server. CA 给每个域名颁发证书后, 都会向 若干个 log server 添加 证书(只能append), 这样 Monitor 就最终会发现这个证书, 验证证书是否是可信的. 对于server传递的证书, Browser/Auditor 在接收到证书后也会检查 Log Server 是否有这样的证书, 只要存在这样的证书, 就可以安心使用(即使这个证书存在问题). 为了保证Log的安全性, 引入了 Merkle Tree, 证明日志中伪造一个证书的不可行. 除此之外, brower 和 monitor 通过 gossip 保证看到的log内容的一致性, 避免日志伪造 (既然都能mock掉log server, 替换掉monitor交互也是可以的, 个人理解也不是100%安全).
问题, log server 运行在哪里? 对于可疑的证书, 怎么处理?
看查阅到的资料, google 就有一个 log server, ca 会将 pre-certificate 发送给google 的 log server. 但是有一个问题, 就是 多个log server 是不同monitor维护, 如果有一个monitor发现有问题, 如果通知其他的 log server 呢?
参考:
- https://www.certificate-transparency.org/what-is-ct
- https://www.certificate-transparency.org/how-ct-works
- https://research.swtch.com/tlog
bitcoin 15
没有论文, 很多细节介绍比较缺失. 比如 节点如何添加到 区块链网络、如何演变成发币. 从目前的理解而言, bitcoin 主要解决了 网络可信任的问题, 使用分布式共识 取代了 第三方信任机构, 分布式共识通过 非对称加密的方式(通常是SHA-256) 进行签名和解密验证, 流程:
对于 double-spend 的场景, 通过 将交易构建成block, 每个block指向前一个block, 构成了 block chain, 对于double-spend, 在广播的时候只有两种情况: 1. 节点同时接受到 两笔交易, 通过校验那么只有一笔会成功 2. 不同节点接受到不同的交易, 分别演化广播, 产生了 两个 block chain, 这种场景下, 是 longest block chain 会成功. 因此, 确定一笔交易会花费很长时间, 对此的解决方案是, 一笔交易的block后续生成5个block就可以得到确认, 每个block的计算都需要花费 10min+, 相当于使用 cpu power 证明 block chain的合法性. 除此之外, 攻击者如果算力超过 50%, 还可以让之前的交易撤销(通过在fork后的版本上构建新的block chain)
pdf 中主要从几个方面讨论了 bitcoin, transaction、timestamp server、proof-of-work、network、Incentive、Reclaiming Disk Space、Simplified Payment Verification、Combining and Splitting Value、Privacy、Calculations 等维度讨论了bitcoin, 在交易这块, 每个transaciton 是 owner 对 (上一次交易+下一个接受者的public key) 的hash 进行签名的结果, 这些交易都会添加到 coin 的末尾, 验证的时候, 只需要有 公钥, 就可以知道这个交易的内容. 问题: 矿机怎么知道owner的公钥?timestamp server 比较特殊, 使用 block 里面item的hash 作为时间进行广播, 这些hash包含了 之前的时间戳, 这样相当于构成了 单链结构, 通过这个结构确定了时间关系(但是并没有比较的功能). proof-of-work 通过 找到 sha-256 hash后前缀大量0的 数, 这个过程耗时比较大, 这个是 block的最重要的一环, 保证了 block 增长的低速 和 一定程度的避免恶意攻击. 那么什么时候可以确定一个block? 整个网络过程如下:
New transactions are broadcast to all nodes.
2) Each node collects new transactions into a block.
3) Each node works on finding a difficult proof-of-work for its block.
4) When a node finds a proof-of-work, it broadcasts the block to all nodes.
5) Nodes accept the block only if all transactions in it are valid and not already spent.
6) Nodes express their acceptance of the block by working on creating the next block in the
chain, using the hash of the accepted block as the previous hash.
很明显, 这里的交易和块是两个环节, 新的交易并发的进入每个节点的新块, 新块在通过 proof-of-work 之后广播出去, 并被接受, 那么这个块里面的事务就会被接受, 其他节点就会基于这个接收的快创建新块. 问题: 在接受新块的时候, 是否要检查下本地是否有交易和新块存在冲突? 原有交易是保留还是全部扔掉?
比较有意思的是, block的第一个交易是block created 的新币, 这就相当于在区块链中发币, 里面讲到 交易输出低于交易输入的值作为 挖矿的费用, 通过这样的机制避免攻击者 (攻击者更愿意赚个钱, 共计成本太高); 在磁盘空间这块, 利用 merkle hash tree 降低了占用.
没看懂, 除了用到 merkle tree 进行校验,以cpu作为支出,大部分算力确保可信
问题:
- 矿机在验证交易的时候怎么知道owner的公钥?
- block 什么时候被添加? 什么时候添加一个新的block?
- 基于hash的timestamp 并没有直接的比较功能, 看样子只能不断解hash, 才能比较两个 timestamp
- item 和 block 是什么关系?
- 什么时候交易的输出低于交易的输入?
- 计算block的hash 是钱吗?应该也需要广播验证的
跟进最近的资料显示, 针对 proof-of-work/pof(耗电, 每次打包block解一道数学题), 还有 权益证明机制(PoS)、POC/Proof of Capacity、 “时空证明机制”(PoST,proof of space time), 有很多内容需要了解
以太坊: 开放的区块链技术, bitcoin 对应 区块链1.0, 中心是货币, 以太坊是区块链 2.0, 中心是 合约. 有人认为 EOS/企业操作系统 是 区块链 3.0, 在于应用
可以深入了解的内容:
- Adam Back’s Hashcash
参考:
- http://www.michaelnielsen.org/ddi/how-the-bitcoin-protocol-actually-works
- https://bitcoin.org/zh_CN/how-it-works
BlockStack 16
blockstack 基于区块链技术实现了网络去中心化, 主要解决的问题是: identity, discovery, storage and survive failures of underlying blockchains. identity 怎么做的?
discovery 这块, 创建了 BNS(Blockchain Name System) 替换目前的DNS, 在设计上借鉴了 NameCoin, 使用区块链实现了分布式, 那么用户怎么注册? 首先, 名字是由 owner加密的区块链地址, 用户注册一个 name 需要两个阶段: preorders + registers, 避免attacker看到未确认交易的时候进行抢占, 除了注册, 还支持更新. BNS中, name 可以等同于 DNS 中 顶级域名, 并挂载到 root blockchain 上. 为了避免恶意抢占大量域名, 通过 “pricing function” 降低这种行为 (但是可能会导致域名越卖越贵, 攒着高价卖). 传统的DNS通过证书增强了安全性, BNS 通过 将 public key 和 name 一起存放实现. 在存储上, 每个 peer-networks 都需要存储 BNS 的zone files, 和 DNS 的一致.
在区块链的抽象上, 将功能和区块链分离, 提出了 “virtual blockchain” 的概念, 在区块链上构建多个状态机, 同时做到了区块链的容灾, 并提出了 fork*-consistency 模型概念, 应用通过回放日志达到 每个block的 application level consensus, consensus hash 依旧是 Merkle hash 的实现, 在fork resolver的处理上呢? 通过10个确认来降低这个可能性.
怎么保证域名的合法性(google的被人抢占了)? 没讲, 需要一套现实系统的迁移映射, 比如 google.com 最好还是叫 google.com
在 blockStack中, blockchain 仅仅存储数据的指针, 而不是真正的数据, 数据存储在 p2p 网络中, 比如 zone files for BNS (类似DNS的zone file), 但是这里用的 p2p 网络并不是传统的实现(容易受到 Sybil attacks), 而是设计了 “Atlas Network”, 保证数据很小, 并且能够全量索引, 也就意味着, 所有的Atlas都有100%的副本, 并使用了 K-regular random graph的策略(Metropolis-Hastings Random Walk 算法), 除了本地存储, 数据也会写入到远程的云存储上 (dropbox/S3), 相比于p2p的DHT, 网络分区和节点恢复 也好很多.
在去中心化存储的设计上, 则是加密写入多个云存储, 为此设计了 Gaia.
个人的感觉上, 最大的亮点反而是 替换了DNS 和 在区块链上构建的 virtual block, 其他存在的问题:
- 只有kv接口, 不能使用复杂的SQL
- 数据共享困难, 为了保证只有数据只被部分人获取, 那么是每个人加密一次, 还是加密(加密数据的)key, 大规模场景下会更复杂
- 能够通过区块链看到别人的数据 (比如通过区块链看到别人的账户)
更多参考 usenix: - https://www.usenix.org/system/files/conference/atc16/atc16_paper-ali.pdf
可以深入的地方: - Name coin - Lets Encrypt - cause forks - Nakamoto consensus - Simple Name Verification (SNV) protocol 补充:
- Sybil attack: 女巫攻击, 在Sybil攻击中,攻击者通过创建大量的假名身份来破坏网络服务的信誉系统,并使用它们获得不成比例的巨大影响力
- Ethereum: 主要用来做 智能合约, 数据和程序都放在用户侧, 容易因为记性不一样造成网络阻塞, 需要学习新的编程语言
- Metropolis-Hastings Random Walk:
扩展
borglet
CHANDRA, T., GRIESEMER, R., AND REDSTONE, J. Paxos made live — An engineering perspective. In Proc. of PODC (2007).
LAMPORT, L. The part-time parliament. ACM TOCS 16, 2 (1998), 133–169
https://www.infoq.cn/article/2010/10/google-percolator?utm_source=related_read&utm_medium=article
AFS? Keybase megastore: https://research.google/pubs/pub36971/
https 加密套件 怎么理解? 一致性 参考 data-sensitive 和 分布式的课程
cops 的 chain replication 的概念和之前的 CRAQ 不同. chain replication 的含义 需要了解下
Chandy-Lamport算法 https://netium.gitlab.io/2019/11/03/%E5%88%86%E5%B8%83%E5%BC%8F%E5%BF%AB%E7%85%A7-Chandy-Lamport%E7%AE%97%E6%B3%95/
???? a.弱一致性(Weak Consistency) b.释放一致性(Release Consistency) c.入口一致性(Entry Consistency)
https://www.cnblogs.com/cchust/p/10703416.html -> https://courses.cs.washington.edu/courses/cse444/08au/544M/READING-LIST/fekete-sigmod2008.pdf 强一致性: https://jepsen.io/consistency https://jepsen.io/consistency
[6].《Distributed Computing,Principles, Algorithms, and Systems》
[7].《Designing Data-Intensive Applications》
一致性模型: lamport
Amazon’s Dynamo [16], LinkedIn’s Project Voldemort [43], and the popular memcached [19]. Facebook’s Cassandra [30] Yahoo!’s PNUTS
公司内的 redis 升级回滚 同城多机房怎么操作呢?
- ceph
- 小图片存储, hystack
- tfs? tair
- fastdfs
https://www.cnblogs.com/wuhuiyuan/p/ceph-small-file-compound-storage.html
滴滴 gift: https://cloud.tencent.com/developer/news/359236 其他的fs: advfs
ceph:
- file:///Users/jianhaixu/Downloads/weil-osdi06.pdf
- https://www.researchgate.net/profile/Ethan_Miller/publication/220851685_Ceph_A_Scalable_High-Performance_Distributed_File_System/links/55e737a808ae21d099c14a71/Ceph-A-Scalable-High-Performance-Distributed-File-System.pdf
fastdfs:
- https://github.com/happyfish100/fastdfs
- 搞个rust client 版本
tfs: 淘宝的文件系统
tair: 淘宝的kv
vertical Paxos: ???
https://zhuanlan.zhihu.com/p/96189481
分布式学习:
Flexible Paxos 论文?
vertical paxos: LAMPORT, L., MALKHI, D., AND ZHOU, L. Vertical Paxos and primary-backup replication. In Proceedings of the 28th ACM Symposium on Principles of Distributed Computing (2009), PODC’09.
2pc: https://zhuanlan.zhihu.com/p/37350460 分布式事务还是得看下: preactor
spanner 深入: Spanner: Becoming a SQL system https://static.googleusercontent.com/media/research.google.com/zh-CN//pubs/archive/46103.pdf
LeanStore: https://db.in.tum.de/~leis/papers/leanstore.pdf
其他论文:
“X-Engine: An optimized storage engine for large-scale E-commerce transaction processing
Optimizing Space Amplification in RocksDB
Co ckroachDB: The Resilient Geo-Distributed SQL Database
hbase tidb 有论文吗 ?
kv 学习: Lak- shman et al. [1] developed Cassandra linkedin Voldemort amazon DeCandia
spark深入: dataFrame
facebook 的 memcache 和 tao 对比下,
参考:
-
作者: Jeffrey Dean, Sanjay Ghemawat: MapReduce: Simplified Data Processing on Large Clusters ↩︎
-
作者: Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung: The Google File System ↩︎
-
作者: Daniel J. Scales, Mike Nelson, and Ganesh Venkitachalam: The Design of a Practical System for Fault-Tolerant Virtual Machines ↩︎
-
作者: Diego Ongaro, John Ousterhout: In Search of an Understandable Consensus Algorithm (Extended Version) ↩︎
-
作者: Diego Ongar: CONSENSUS: BRIDGING THEORY AND PRACTICE ↩︎
-
作者: Patrick Hunt, Mahadev Konar, Flavio P. Junqueira, Benjamin Reed: ZooKeeper: Wait-free coordination for Internet-scale systems ↩︎
-
作者: Jeff Terrace, Michael J. Freedman:Object Storage on CRAQ High-throughput chain replication for read-mostly workloads ↩︎
-
作者: Amazon Web Services: Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases ↩︎
-
作者: Chandramohan A. Thekkath, Timothy Mann, Edward K. Lee: Frangipani: A Scalable Distributed File System ↩︎
-
作者: Google, Inc.: Spanner: Google’s Globally-Distributed Database ↩︎
-
作者: Microsoft Research: No compromises: distributed transactions with consistency, availability, and performance ↩︎
-
作者: University of California, Berkeley, Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing ↩︎
-
作者: Facebook Inc: Scaling Memcache at Facebook ↩︎
-
作者: Princeton University: Don’t Settle for Eventual: Scalable Causal Consistency for Wide-Area Storage with COPS ↩︎
-
作者: https://bitcoin.org: Bitcoin: A Peer-to-Peer Electronic Cash System ↩︎
-
作者: Muneeb Ali, Ryan Shea, Jude Nelson, Michael J. Freedman: Blockstack Technical Whitepaper ↩︎