5 minutes
Google_article
序
读论文的路上继续. 这里主要围绕 spanner sql 、megaStore、F1、dremel 相关的论文.
spanner sql 1
在之前spanner kv的基础上, 主要介绍了sql的实现(从kv->rdbms), 不同于其他sql+存储松耦合的实现方式(两套系统), spanner 采取了内部紧耦合的策略. 除了sql, 还提及了一个新的数据存储格式: Ressi, 和 SSTable 不同的是, block之间是面向 row的, 但是block内部存储却是面向 列的, 这样既保留了 rowkey 的有序性, 还让单个column的读取更加高效. 除此之外, 还支持冷热数据(老版本数据被放在inactive files) 以及 大value另外存储(避免不必要的读取), Ressi 的底层数据结构是 vector(能够更好的压缩).
sql的研究方面, 介绍了 QUERY DISTRIBUTION (Distributed query compilation 、Distributed Execution、 Distributed joins、Query distribution APIs), QUERY RANGE EXTRACTION(Compile-time rewriting、Filter tree), QUERY RESTARTS(用户体验上的提升, ), 除此之外, 还使用了公司统一的SQL Diaect, 重点介绍了测试. (没有太深的经验, 勿喷)
ps: 建议重试相关工作的时候在读一遍, 没看太懂(不是很想话时间立即学习…)
可以参考: https://zhuanlan.zhihu.com/p/27544985 学习下
问题:
- sql 的入口和请求处理在哪里?谁负责合并unoin响应? distributed join 和 distributed apply.
看论文, 感觉是 任意一台spanner服务器.
megaStore 2
基于 bigtable 实现了 traditional RDBMS 功能, 提供了 interactive service, 通过同步复制达到高可用, 除此之外, 也是将数据分区(抽象了entity group), 每个分区独立复制, 支持二级索引等功能, 以及 partition内部的 scheme.
问题:
-
bigtable 本身就是paxos同步的, 为什么还需要自己写个paxos?
-
全局索引的存储
-
数据模型&feature
底层基于bigtable存储数据, pk: rowkey, tableName+column Name 作为 bigtable的列名, 来区分不同的table, 这样不同table的主键可以存储在一起, 方便查询.
在可扩展性上, 将数据分区, 每个分区抽象为 “entity groups"的集合, 通过分区, 可以实现 单个 entity group 内部的 ACID 事务(paxos复制), entity group 的边界选择上, 论文中举了 Email、Blogs、Maps, 主要是尽量避免跨组的操作, 实现group操作内聚.
entity group 由一个 root entity 和 多个 child entities, root entities 存储在 root table, child entities 存储在 child table, (也就是说, Megastore tables 由 root tables 和 child tables 构成, child table 通过 外键引用 root table的数据), 每个 entity 就是一个 Bigtable 的一个row. 针对递增的key, 通过前缀添加两个字节的hash 进行scatter避免 局部热点. root entity 存储 事务和复制的元数据(复制日志),
比较注意的是, root entity 也是存储数据的, 比如 论文中 user 是 root entity, photo 是 child entity.
索引的设计上, 也有 单个 entity group 内部的 local index, 还有global index(没有说存在哪里, 估计是单独的bigtable). 除此之外, 还支持 Storing Clause(索引内部存储额外数据, 减少pk数据的读取) 、Repeated Indexes、Inline Indexes(从例子上比较好理解. user table 和 photo table, 查询 user 的所有photo 的方式中, 经常是 user某个时间范围或者时间点的 照片, 那么就需要 user+publish timestamp 做一个索引, 这里的做法就是, user id 作为rowkey, 将 photo publish timestamp 作为 column 存储起来, value 就是 photo 的 id). 对标存储结构上, 每个索引是 root table pk+index value+pk, 比如 (user id, time, primary key), repeated index 是每个field一个 entry. 除此之外, 也支持全文索引
对外的api上, 没有支持 join 操作,依赖应用程序自己实现.
schemas设计 除了对标 RDBMS, 还支持了 pb类型, 以及 申明key是升级还是降级.
写入上, 是先通过paxos同步操作的wal, 然后apply写入bigtable, 事务通过 timestamp实现 mvcc. 读取提供了 “current, snapshot, and inconsistent” 三种. Current and snapshot 都是entity group内部的, 需要等待前面的write被applied, 比较有意思的是, write transaction 需要一次 current read来获取下一个 log position, commit operation 将所有写聚合成一个 log entry, 并 通过paxos 协议append 到 log. (log position的处理可以参考paxos协议)
跨entity group的写事务 通过 queue + async实现, 同时也支持 two-phase commit 来做 atomic update(但是不鼓励).
其他的设计:
- 灾备的考虑, 除了副本, 还有 full snapshot.
- 加密
- 复制
在复制模型上, 评估了三种复制模型: 同步/异步/乐观复制(类似多主), 最后选择了paxos, 通过复制 wal 来同步(同步成功后, 数据写入bigtable). megaStore创新的优化: 最新副本的local read(避免走paxos流程), 一轮的写(paxos需要两阶段), 分别也叫 fast read 和 fast write. 根据数据模型的特征, 每个分区运行独立的 paxos, 这里称之为 “multiple replicated logs”.
典型的paxos write需要两轮操作: prepares + accepts, read 也需要一轮确定最新的value. 业界常规的优化是 master-lease (batch write, 减少一次prepare, 因为放到了 accept里面了, 读走master). 但是这种设计, 会导致 slave资源浪费,master资源热点,master failover 需要复杂的流程(状态流转+timer). megastore 设计中, 通过coordinator的设计, coordinator 跟踪哪些已经是最新写入的 副本(意味着数据是最新的), 达到了 local read 的效果. 但是这就需要 write流程的改动(writer过程需要coordinator登记, 中间写入失败也需要 invalidate), 在write的优化上, 也和业界不一样, 论文称之为 “leaders”, 每个 log position 都是一轮 paxos, 每个 log position 的leader 都是不一样的副本, 只有第一个提交给leader的才会被accept, 其他写入会退化成 两轮的 paxos, leader 的选择也是基于write submit的观察(coordinator?) 这种设计可以让 writer 选择最近的副本. leader 的确立也是通过 accept流程中被 接受的. 因为写入可能中间失败, 因此 coordinator 还需要支持 invalidation.
除此之外, 还支持 乱序proposal(没细讲). 读取优化上, coordinator的参与, 可以判断本地是否是最新的, 如果不是最新, 可以选择一个 responseive 或者 最新的 副本执行 catch-up/追赶(可能需要paxos执行no-op处理没有提交的value), 在正式apply前, 会更新下 coordinator的信息.
coordinator的引入会导致一些可用性问题, 不过按照论文的说法, coordinator实现比较简单), 在 coordinator出现问题的时候, writer leader 会退化到 两阶段paxos, 解决 n+1 log position 需要投票. 而带来的好处: 1. 简单没什么依赖 2. workload很大 3. 轻量级网络流量, 更高的QOS 4. chubby 加持 5. 可禁止
除此之外, coordinator 为了解决多副本 读吞吐量问题的, 会影响write, 导致 outage, coordinator 拿的是 另个机房的锁, 这个时候存在 coordinator 和 对端机房的chubby 一起分区了, 需要手动操作… 另外, client 尽量一个, 避免回退到paxos.
比较有意识的是, 提出 commit point 和 visibility point 的概念.
在副本设计上, 不仅仅有 full replica, 还有 Witnesses replca(只投票, 不apply), 以及 read-only replica.
在实践上, 也特意提到了 随机测试框架, 提前发现了很多问题. 因为底层依赖 bigtable, MegaStore直接将控制权交给了用户, 让用户配置(所以查询慢了, 用户也需要直接找bigtable).
percolater 3
为了解决 Map/Reduce 新增索引无法实时的问题(因为需要批量), 设计了 percolator, 通过observer的实现了 新增变更实时处理的效果. observer机制需要依赖 1. timestamp oracle(提供严格递增的时间戳, 用于快照隔离机制) 和 2. 轻量级锁服务(更高效的搜索脏的通知). percolator 和 megaStore 类似, percolator 也是基于 bigtable的, 但是提供bigtable没有提供的多行事务 以及 observer.
设计上, 锁信息 作为column family 存储在 row的数据中: c:lock、c:write、c:notif、c:ack O. 用于多个事务的排序(避免冲突) 以及 失败解决. 还特意设计了 primary lock(多个事务的其中一个cell) 避免多个事务之间的 commit/delete. 为了避免worker分配到任务 没有执行, 使用了 chubby token(aliver) + wall time(blocking).
其他的feature: 有个特殊的设计, 多个事务变更, 只会有一次notify用于observer正在处理. 为了避免 scan 的聚集问题 (多线程扫描一块区域, 导致热点), 采取了随机化的策略. 为了提高性能, 采用了聚合读写 以及 predict read.
事件上, 改写了原来的indx服务, 性能提升了很大: 100x.
缺陷: observer 是链接进去的, 看上去不能动态加载.
dremel
定位在 只读嵌套类型数据的即席查询, 支持兆级别的数据量. 和 Pig、Hive 不同, 并不需要将查询语句 翻译成 MR 的任务, 在存储格式上, 使用 column-striped 存储, 并提出了 Repetition 和 Definition Levels, Repetition Level: 定义了 value 在 field path 的 哪个 field 上重复了, 注意, 新的记录是 0, 并且 required/optional 是不计算路径的, 通过repitition level可以知道下一个列是不是新的列, 这样就可以通过构建 FSM 来处理列式数据了 (个人比较郁闷的是, 应该是分散存储的呀, 怎么会需要这个FSM呢?). Definition levels: 该列的路径上有多少个可选的field被定义了, required 不参与计算. 如果 definition level 低于 repeated/optional fields 数量的, 表明这个字段是个 NULL, 因此就直接存储 definition level 而不需要存储一个 NULL 了, difinition level 和 repitition level 都是 bit. 通过 field writers 将 record 转换为 column格式, 在 column 转换为 record 格式的处理上, 采用了 FSM 的设计. 基于SQL设计了一套查询语言, 架构上采用了 multi-level serving tree的设计, 也常规的使用 Query dispatche 进行物理计划执行, 并且抽象了 slot 的概念 (一个slot对应一个线程), 其他最慢节点的重新调度.
列式到存储上需要一层转换. 没有太多的经验, 直观感受比较低. repitition level 和 difinition level 在 Data sensitive 那本书中也有介绍, 另外 parquet 挺流行的. 开源版本可以参照 Drill.
borg
borg 是google 内部集群管理工具, 整体架构上来讲和 k8s 还是存在一定差异的, 如下:
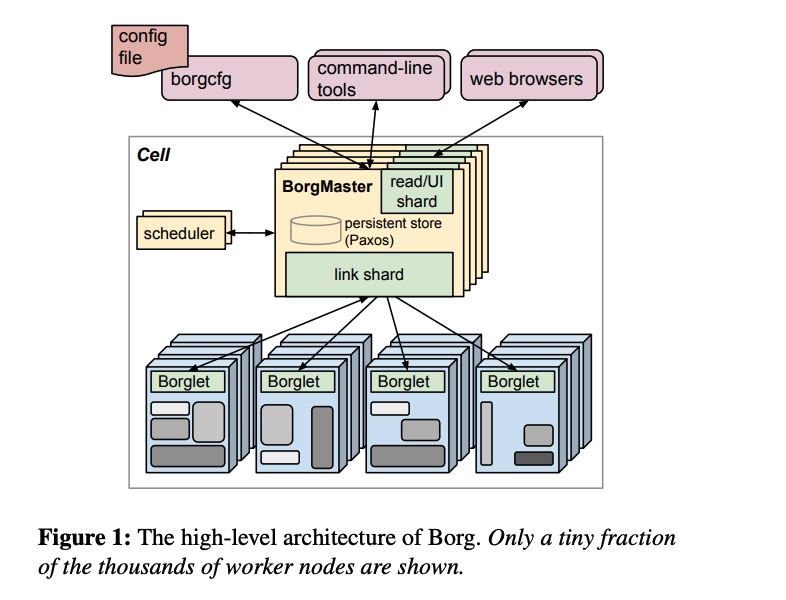
在部署上, cell 表示一个管理单元, 内部由多台机器组成, 一个集群有多个cell (个人理解比如 ppe、prod、test分别是一个cell), 一个dc有多个cluster.
架构上, 主要是 中心化控制节点 borg master + 机器上的agent进程 Borglet 构成. 其中, borg master 是由 main process 和 scheduler process 组成, main process 是管理接口: job 的提交和查询、资源的管理(machines/tasks/allocs…)、borglet的交互, 状态的管理是通过paxos协议实现(快照+changelog, 存储在本地磁盘), 为了能够被其他服务访问, master 也需要注册到 chubby 上. scheduler 负责将任务分配到机器上, 调度存在两个环节: feasibility checking + scoring (选择最合适的, 采用了 E-PVM)(后续优化中, scheduler也被拆分成了多个进程, 评分缓存、通过随机化减低全部机器计算的开销). Borglet 部署在每个机器上, 负责 start/stop tasks、滚动升级 等.
设计使用上, 用户以job的方式提交服务, 一个job包含多个task. borg 区分了两种任务类型: pord(延迟敏感) 和 non-prod(以batch为主).
术语上, alloc 是分配的资源用于job运行的, 常规的 priority、quota、admission control, 其中, 基于 chubby 提供了 BNS(borg naming service), 用于节点的服务发现, 详细的信息存储在 dremel 可查询的 Infrastore 中.
有意思的是, 在 google内部, GFS 、Bigtable、MegaStore、MapReduce、FlumeJava 等都构建在 borg之上
Dapper
很老的论文了, 在开眼世界的替代品很多, 比如 pinpoint、cat、skywalking、zipkin 等, 这些开源项目在很多公司都有很大的使用. 目前 还有了相关标准: jagger. 很多轮子现在都适配和支持了 jager 的客户端协议, 使用起来会更加丝滑.
dapper 致力于 低负载(通过提供开关、采样)、应用层级透明(框架集成)、可扩展, 在功能上, 还支持了 annotation, 可以让业务自定义 一些信息.
在整体架构上, 和之前的了解差异不大, 日志写文件, 由 dapper daemon 读取文件, 通过 dapper collectors 投递到 bigtables. 为了更好的服务给业务方, 提供了多种形式的接口获取, 除了 tracId access、bulk access、indexed access, 还支持对外的api, 从而产生更多的产品.
使用dapper方面,更多的总结了相关经验: 和异常相结合(这里存在一个反馈上游落地日志, 不然采样可能采不到), 长尾延迟, 服务间相互影响, 网络使用率, 分层和共享存储.
pregel
to-do
Infrastore? E-PVM? Omega
参考
-
作者: Google, Inc: Spanner: Becoming a SQL System ↩︎
-
作者: Google, Inc: Megastore: Providing Scalable, Highly Available Storage for Interactive Services ↩︎
-
作者: Google, Inc: Large-scale Incremental Processing Using Distributed Transactions and Notifications ↩︎